
Even the chip makers are making LLMs
Ryan welcomes Kari Briski, NVIDIA’s VP of Generative AI Software for Enterprise, to the show to explore how a chip manufacturer got into the model development game.
March 10, 2026
Entertainment news, movies, and celebrities
Ryan welcomes Kari Briski, NVIDIA’s VP of Generative AI Software for Enterprise, to the show to explore how a chip manufacturer got into the model development game.

Rspress 2.0 has launched with a revamped theme, boosted performance, and innovative AI features, transforming developer documentation. With enhanced build speeds and a new Static Site Generation to Ma...

Microsoft has released version 1.0 of the official MCP C# SDK, bringing full support for the 2025-11-25 MCP Specification. The release introduces enhanced authorization flows, icon support for tools a...

In this episode, Thomas Betts and Sam McAfee discuss how AI hype is reshaping organizational behavior, why many companies struggle with experimentation, and how unclear decision structures create fric...

This week's Java roundup for March 2nd, 2026, features news highlighting: the GA release of Apache Solr 10; point releases of LangChain4j, JobRunr, Multik and Gradle; maintenance releases of Grails an...

Patrick Debois discusses the evolution of software engineering in the age of AI. He shares four key patterns: transitioning from producer to manager, focusing on intent over implementation through spe...
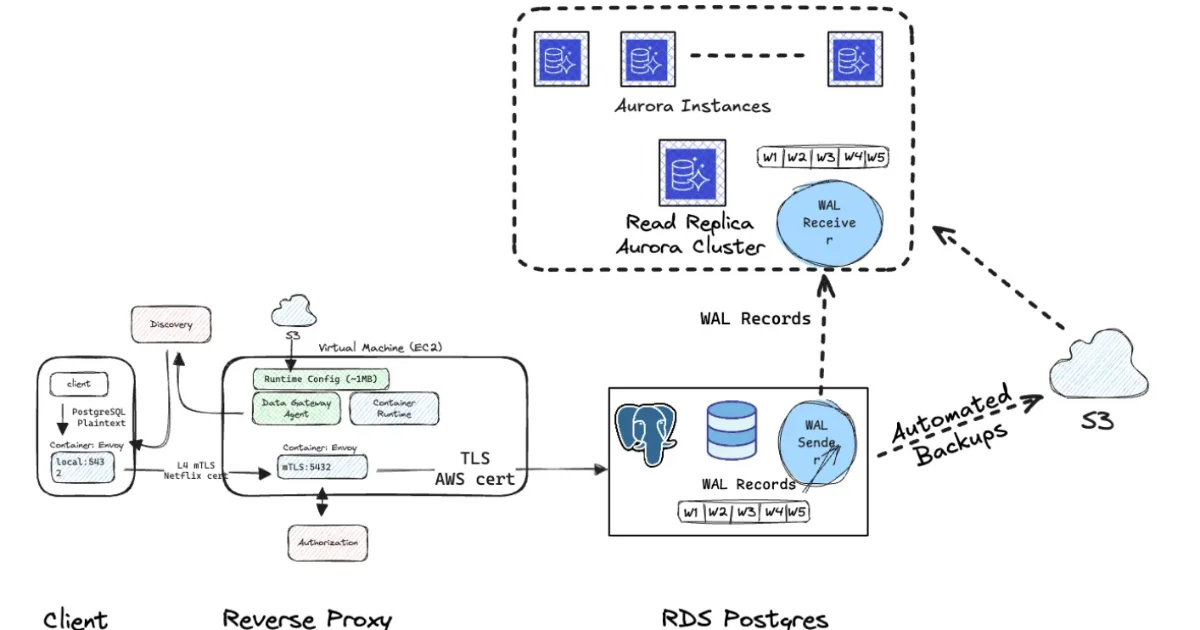
Netflix engineers describe an internal automation platform that migrates nearly 400 RDS PostgreSQL clusters to Aurora, reducing downtime and operational risk. The platform coordinates replication, CDC...

Cloudflare released vinext, an experimental Next.js reimplementation built on Vite by one engineer, with AI guidance over one week, for $1,100. Early benchmarks show 4.4x faster builds, but Cloudflare...

Artificial intelligence is rapidly transforming how software vulnerabilities are detected, but questions about who governs the risks AI exposes, and how those risks are acted on, are becoming increasi...

After the Datadog Agent grew from 428 MiB to 1.22 GiB over a period of 5 years, Datadog engineers set out to reduce its binary size. They discovered that most Go binary bloat comes from hidden depende...

Uno Platform 6.5 introduces Antigravity AI agent support, allowing agents to verify app behavior at runtime. Hot Design now launches by default with a redesigned toolbar and new scope selector. The re...

AI-powered bot hackerbot-claw exploited GitHub Actions workflows across Microsoft, DataDog, and CNCF projects over 7 days using 5 attack techniques. Bot achieved RCE in 5 of 7 targets, stole GitHub to...

Andre Ribeiro discusses the architecture of Healthily’s AI symptom checker. He explains how Bayesian inference and RAG models bridge the gap between medical insights and confident patient action. By A...
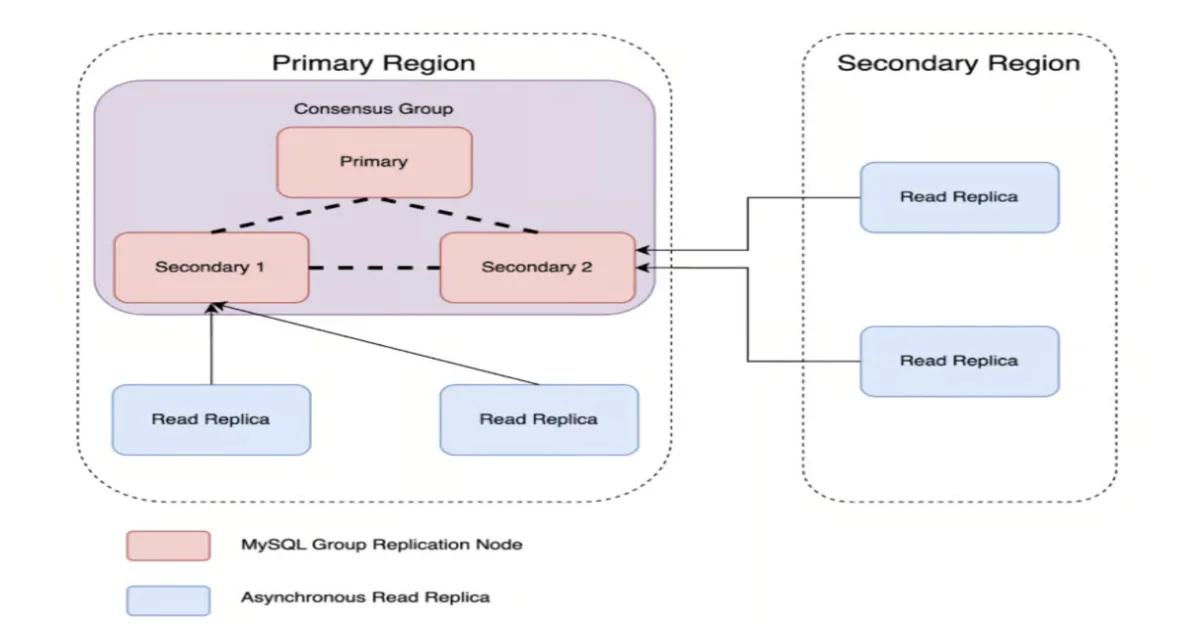
Uber redesigned its MySQL fleet using a consensus-driven architecture based on MySQL Group Replication, reducing cluster failover time from minutes to seconds. By moving leader election and failure de...

Webpack's 2026 roadmap, led by Even Stensberg, unveils substantial enhancements aimed at modernizing the bundler. Key features include native CSS module support, universal compilation for various envi...

Every MCP tutorial I've found so far has followed the same basic script: build a server, point Claude Desktop at it, screenshot the chat window, done. This is fine if you want a demo. But it's not fin

Finding the top K items in a dataset pops up everywhere: from highlighting the hottest posts in a social feed, to detecting the largest transactions in a financial system, or spotting the heaviest use

Ever wondered how Gmail knows that an email promising you $10 million is spam? Or how it catches those "You've won a free iPhone!" messages before they reach your inbox? In this tutorial, you'll build

Hey there! If you're building modern web interfaces, chances are you've already fallen in love with Tailwind CSS for its speed and flexibility. One of the most powerful tools in Tailwind's arsenal is

Most RAG tutorials end the same way: you've got a working prototype and a bill for a vector database that runs whether anyone's querying it or not. Add an always-on embedding service, a hosted LLM end